美国斯坦福大学的一个AI(人工智能)团队就抄袭中国大模型致歉。
近日,由三位美国斯坦福大学学生组成的一个AI团队发布了开源模型Llama3-V。但是,该模型很快被曝出与中国大模型公司面壁智能的开源成果拥有几乎完全相同的模型架构与代码,引发“抄袭”质疑。
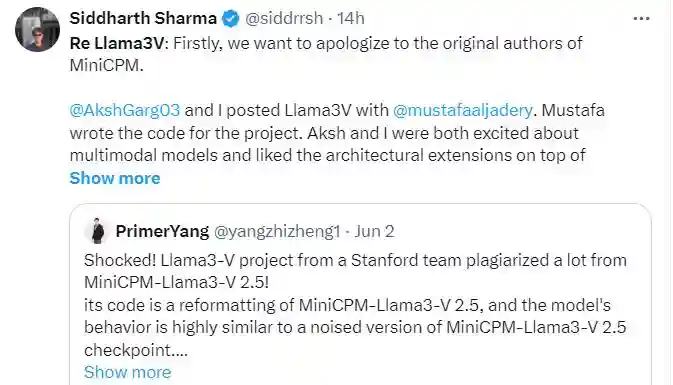
当地时间6月3日,Llama3-V团队的两位作者森德哈斯·沙玛(SiddharthSharma)和阿克沙·加格(AkshGarg)在社交平台X上发布文章,向MiniCPM团队正式道歉,表示会将Llama3-V模型从网络上撤下。
在道歉信中,沙玛和加格称他们负责模型的宣发工作,该模型代码的作者是穆斯塔法·阿尔贾德里(MustafaAljadery),但两人在看到相关质疑后于6月2日询问了阿尔贾德里,此后再也没能联系上后者,于是决定发布道歉声明。
目前,阿尔贾德里的X账号显示“仅好友可见”,Llama3-V模型也已经从HuggingFace等开源平台上下架。不过,加格还在发布Llama3-V的Medium页面上保留了一些描述和介绍,在开头附上了道歉声明。

公开资料显示,北京面壁智能科技有限责任公司成立于2022年8月,核心产品包括全流程大模型高效加速平台ModelForce和CPM大模型。今年4月,面壁智能完成新一轮数亿元融资,由华为哈勃领投,春华创投、北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。
在该团队道歉前,面壁智能的联合创始人兼CEO李大海已在朋友圈发文回应,披露了Llama3-V能够与MiniCPM一样识别出“清华简”战国古文字的新证据,而由MiniCPM团队扫描并人工批注的该古文字数据并未对外公开,证实了Llama3-V模型涉嫌抄袭。

面壁智能CEO李大海的朋友圈回应
这场风波起源于5月29日。当日,斯坦福大学的一个研究团队在开源社区中发布了名为“Llama3-V”的模型,称只要500美元(约合人民币3622元)就能训练出一个SOTA多模态模型,且效果比肩知名大模型GPT-4V、GeminiUltra与ClaudeOpus。
然而,不久后,开源社区内开始出现怀疑声,质疑Llama3-V是在“套壳”面壁智能于今年5月中旬刚刚发布的最新8B多模态小模型,且没有在项目中提到任何关于后者的信息。
对此,Llama3-V团队回应称其“只是使用了的tokenizer(分词器)”,并称团队在发布前就已经开始了这项工作。
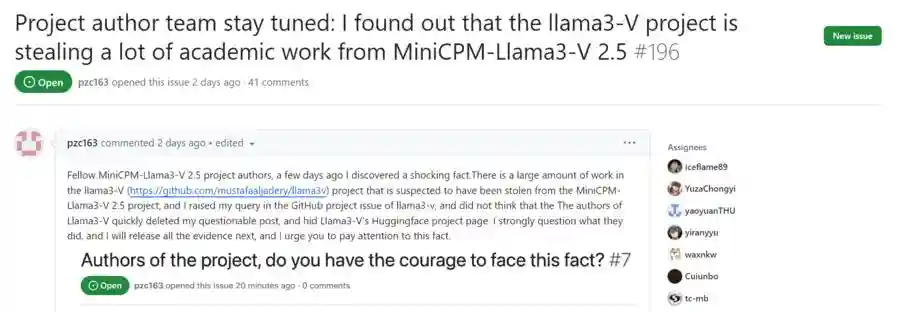
证据显示,Llama3-V项目使用了与项目基本完全相同的模型结构和代码实现。另外,HuggingFace发布页面上的历史记录显示,Llama3-V的作者曾在该页面上直接导入了MiniCPM-V的代码,然后改名为Llama3-V。
值得一提的是,在Llama3-V团队道歉前,斯坦福人工智能实验室主任克里斯托弗·大卫·曼宁(ChristopherDavidManning)也在X平台上发文谴责这一抄袭行为,并称MiniCPM“是很好的开源作品”。
对于此事,面壁智能首席科学家、清华大学长聘副教授刘知远也在知乎上发表了回应,称这次事件让他感慨“过去十几年科研经历的斗转星移”:“从横向来看,我们显然仍与国际顶尖工作如Sora和GPT-4o有显著差距;同时,从纵向来看,我们已经从十几年的nobody,快速成长为人工智能科技创新的关键推动者。面向即将到来的AGI时代,我们应该更加自信积极地投身其中。”